

Putting your infrastructure in the cloud has a lot of benefits. Some highlights include:
- Fine-grained cost control based on a pay-as-you-go model. If you think of compute time as a commodity, there are now new pricing models like Spot Pricing and Reserved Instances that give you new ways to manage cost.
- Increased flexibility to create and destroy application environments as you need them.
- Free up the valuable time of system administrators and/or developers from data center maintenance tasks like replacing failed hard drives, upgrading network switch firmware, etc.
Rather than thinking about cloud resources as just another bunch of servers to configure, I prefer to think of the cloud as providing an API that lets me programmatically design and control my infrastructure. Our goal should be to design an infrastructure stack that is composable and repeatable so that we can leverage it to create multiple different environments in exactly the same way (e.g. production, staging, testing).
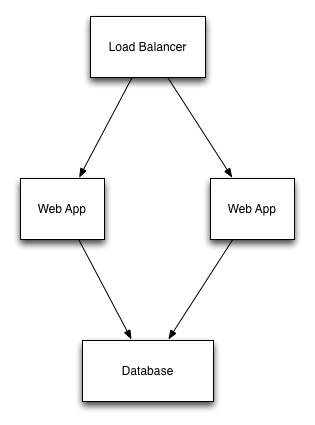
Let's use a concrete example to illustrate some of these issues. We'll use a common example that most people are familiar with: a load-balanced web application that uses a database deployed in Amazon Web Services. I've included a diagram below.
Using Configuration Management
In the early days we would have provisioned these servers using the AWS API, the CLI, or the AWS Console, then used Chef/Ansible/Puppet/Salt (CAPS) to configure the servers.
Over time, our configuration management tools became smarter and allowed us to create cloud resources. This let us consolidate the number of tools we use to manage those cloud resources.
Cloud APIs have dependencies that must be met before a resource can be created. For example, you must create a Security Group Rule before creating an EC2 instance and assigning the rule. We also have dependencies within our stack in terms of which resources should be created first. In our example web application, the database server should be created prior to creating the application servers. And the application servers should be created before the load balancer. If we're tearing down a stack (say we're done with our personal testing environment), we'll want to do this in reverse order.
Here's an example using Ansible to create and destroy the two web application servers.
---
- hosts: localhost
gather_facts: False
tags:
- create_stack
vars:
vpc_id: "vpc-abc123"
vpc_subnet_id: "subnet-xyz456"
key_name: "jramnani-work"
tasks:
- name: "Create Security Group"
ec2_group:
state: present
name: webapp
region: "us-west-2"
description: "Firewall rules for web servers"
vpc_id: ""
rules:
- proto: tcp
from_port: 80
to_port: 80
cidr_ip: "0.0.0.0/24"
- proto: tcp
from_port: 22
to_port: 22
cidr_ip: "0.0.0.0/24"
- name: "Create EC2 instances"
ec2:
region: "us-west-2"
key_name: ""
instance_type: "t2.micro"
image: "ami-90f551f0"
wait: yes
vpc_subnet_id: ""
assign_public_ip: yes
instance_tags: { "env": "test", "tier": "web" }
exact_count: 2
count_tag: { "env": "test", "tier": "web" }
groups: "webapp"
- hosts: localhost
gather_facts: False
tags:
- destroy_stack
vars:
ec2_instance_ids: []
tasks:
- name: "Destroy EC2 instances"
ec2:
state: absent
region: "us-west-2"
instance_ids: ""
What's important in this example is that we're managing two plays—one to create the stack, and one to destroy it. It's very similar to managing database migrations in Rails or Django.
Now, my question for you is: do you see anything missing?
I forgot to clean up the Security Group. So now I'm leaking Security Groups and should clean them up. It's easy to see in a stack this small, but it's not hard to extrapolate from this example how easy it would be to leak resources in a much larger stack.
Also make note of two of the arguments passed to the Ansible ec2 module module: exact_count and count_tag. These two arguments tell Ansible how to manage the state of the EC2 instances. Without these tags, Ansible would create two new EC2 instances each time you ran the playbook. With these two tags in place you can run the playbook twice, and if the two EC2 instances are still online, it won't create new ones. Also, if you want to add more instances, you can increase the value of exact_count.
Summary
There are many ways to manage cloud resources, and using CAPS is one of them. Let's summarize some of the trade-offs.
- It's easy to get started managing cloud resources if you already have experience or investment in CAPS.
- You must remember to manage the state of the stack so you don't mistakenly create new cloud resources like Tribbles.
- Cloud APIs have dependencies between resources. It's up to you to create the resources in the correct order.
- You should be able to destroy an environment automatically as easily as you can create them. To do so, you'll need to create and maintain code that destroys a stack in the correct order, and doesn't leak resources.



