

And before you flee in horror from the words “distributed systems,” remember that even a tiny React app with a Node backend, or a simple iOS client talking to AWS Lambda, represents a distributed system. As you read this blog post, you are already participating in a distributed system that includes your web browser, a content delivery network, and a file storage system.
In terms of background, I’ll assume for this post that you understand how to make API calls and handle their success and failure in a language of your choice, but it doesn’t matter whether those API calls are synchronous or asynchronous, HTTP or not. Don’t worry if you hit an unfamiliar term or idea! I’m happy to talk more on Twitter or elsewhere, and I’ve also tried to include links where appropriate.
The issue we’ll be exploring is this: if we encounter a very, very slow API call that eventually times out, and we assume either (a) it succeeded or (b) it failed, we’re going to have bugs. Timeouts (or worse, infinitely long waiting) are a fundamental fact of life with distributed systems, and we need to know how to handle them.
The Problem
Let’s start with a thought experiment: have you ever emailed a coworker to ask them for something?
- [Tuesday, 9:58am] You: “Hey, can you add me to our company’s list of potential mentors?”
- Coworker: “…”
- [Friday, 2:30pm] You: [?]
What should you do?
If you want your request to be fulfilled, you’ll eventually need to decide that an answer isn’t coming back. Do you wait longer? How long do you want to wait?
Then, once you’ve decided how long to wait, what action do you take? Do you try emailing again? Do you try a different communication medium? Do you assume they won’t do it?
OK, now what really happened here? We wanted to see this kind of request-response behavior:
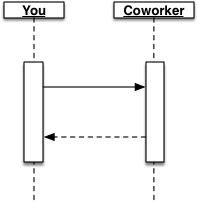
But something went wrong. There are several possibilities:
-
They never got the message.

-
They got the message, processed it successfully, and sent you back a response that never got to you (or went to your spam folder).

-
They got the message, and they’re still thinking about it, or they lost it, or [gasp!] they forgot.

Ultimately, we just don’t know!
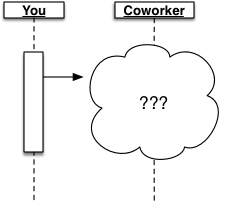
Precisely this problem arises with any communication across a distributed system.
We might have our requests, processing, or responses delayed, and those delays might be arbitrarily long. So as with the email example, we need to ensure that the “how long do we wait?” question has an answer, and we call that duration a timeout.
If you only take one lesson away from this article, let it be this: use timeouts. Otherwise, you’re risking waiting forever for an operation that will never complete.
But once we hit that timeout, that upper limit on waiting, what do we do?
Approaches
There are several common approaches that people take when they experience a timeout in a remote system call. I don’t claim that this list is exhaustive, but it does cover many of the most common scenarios I’ve seen.
Approach #1
When you hit a timeout, assume it succeeded and move on.
Please don’t do this.[1] Unfortunately, I have to say this is a common unconscious choice even in production applications, with some very sad UX outcomes. If we assume an operation succeeded, our poor consumer reasonably assumes that things went fine—only to be disappointed and confused later on when they discover the results.
Anytime you have a network call, look for both success and failure cases. For example, if you’re using an asynchronous API in JavaScript with Promise.then(…), please ask yourself where the corresponding .catch(…) is. If it’s missing, you’ve almost certainly got a bug.
In some very specialized cases, you might legitimately not care if the request succeeds or fails. UDP is a very successful protocol that has this property. Plus, lots of software is broken, and continues to make money just fine! But please don’t let this be your default—exhaust your other options first.
Approach #2
For read requests, use a cached or default value.
If your request is a read request and isn’t intended to have any effects on the remote end, this could be a good bet. In this case, you could use a cached value from a previous successful request. Or you could use a default value, if there have been no successful requests yet or if caching doesn’t make sense in your situation. This approach is relatively simple: it doesn’t add much performance overhead or implementation complexity. But do keep in mind that if you’re using an out-of-process cache that you access over the network (e.g., memcached, Redis, etc.), then you’re back in a similar situation where your requests to the cache itself may time out.
Approach #3
When you hit a timeout, assume the remote operation failed, and try again automatically.
This raises more questions:
- What if it’s not safe to retry? Is it just an annoyance for the service on the other end of the network connection to get duplicates? Or are you double-charging a credit card? (!)
- Should you retry synchronously or asynchronously?
- If you retry synchronously, those retries will slow you down from your consumers’ perspective—are you at risk of not meeting their expectations? This is particularly important in services, as opposed to end-user applications.
- If you retry asynchronously, what do you tell your consumer about the operation’s success? Do you try one at a time, or batch the retries up for some period?
- How many times should you retry? (once? twice? 10 times? until it succeeds?)
- How should you delay between retries? (exponential backoff [e.g., 1s, 2s, 4s, 8s, 16s, ...] bounded by a maximum wait time? using jitter?)
- If the remote server is having performance issues due to being overloaded, will retrying make their situation even worse?
If a remote API is safe to retry, we call it idempotent. Without the idempotent property, you could create duplicate data (as in the case of credit card charges) or cause race conditions (i.e., if you attempt to change your email address twice, and the first one is retried after the second one completes).
In many cases, making automatic retries safe could require major architectural effort. But if you can retry safely (e.g., by sending along a request UUID, and having the remote end keep track of these) things get much, much simpler. Check out the Stripe API for a good example of what this could look like in practice.
Approach #4
Check and see if the request succeeded, and try again if it’s safe.
The idea here is that in some cases, we can follow our timed-out request up with another request asking about the status of our original request. This approach clearly requires the existence of an endpoint that can give us the information we want. Given such an endpoint, if the endpoint says our request was successful, we can say definitively that we don’t need to retry.
But there’s a serious problem here, in that we can’t really know if a retry is safe. Because in general a request could be received by our remote service, but still be in-process, and therefore the query endpoint we’re checking would be unable to confirm success. And of course, the check itself could time out! The remote server may be completely unreachable for the same reason as the initial failure, but even if that’s true, we still can’t know whether the problem happened before or after our initial request was processed.
Approach #5
Give up and punt to the user to figure it out.
This takes the least effort, and arguably prevents us from making an incorrect decision, so this could be the best option in many cases. We also need to ask ourselves: can our user figure out the right thing to do? Do they have sufficient information and insight into other systems to determine how to move forward?
Letting our consumers know about the issue may be the best option in some cases. With any of the approaches involving retries, we may still fall back to this path eventually, if we don’t want to allow an unbounded number of retries!
Conclusions
So at this point, things might seem bleak. Distributed systems are hard, and it seems we can’t just pick one of these solutions as a silver bullet. If you’re feeling defeated, take heart, and don’t let perfect be the enemy of good.
Use timeouts.
Even if it’s a pretty long timeout, like 5 seconds, 10 seconds, or [gulp!] even more, every network request ought to have some timeout in place. Picking a timeout can be tricky—you don’t want to have too many failures when requests will ultimately succeed (false negatives), nor do you want to waste too much time and risk an unhealthy application. You may be able to determine good values by looking at the distributions and trends of historical requests, along with your application’s own performance guarantees or risk profile.
In any case, we don’t want our app servers’ queues, connection pools, ring buffers, or any bottleneck jamming up with stuff that’s going to wait forever. You can definitely research and add fancier things like circuit breakers and bulkheads depending on your production needs, but timeouts are cheap and well-supported by libraries. Use them!
Default to making retries safe.
Besides making your code simpler and safer, you’ll get to say “idempotence,” which is very fun.
Consider delegating work in a different way.
Asynchronous messaging has some appealing properties here, in that your remote service no longer needs to stay fast and available; only your message broker does. However, messaging / asynchronicity isn’t a silver bullet—you’ll still need to make sure the broker gets the message. This can be hard, unfortunately! Message brokers have tradeoffs too. And your users will have their own ideas about when they need to retry. If message processing is delayed, for example, they may decide to resubmit because their order hasn’t yet shown up in order history. Similar issues can arise in distributed log / streaming platforms. If you’re considering the messaging route (and really, even if not!), please take a good look at Enterprise Integration Patterns—despite its age, the patterns there are extremely relevant to today’s architectures.
And at the risk of being a party pooper, don’t forget that you might be able to move or remove that network boundary altogether! There’s no shame in taking a hard problem and turning it into an easy problem. So maybe you can use one network request instead of five, or maybe you can inline two services together. Or maybe you take one of the approaches above to handle timeouts in a reliable and safe way. Whichever path you choose, remember, your users don’t care if you’re using microservices or not—they just want things to work.
Learn More
I can heartily recommend these resources to dig in further:
- “Two Generals’ Problem” (article)
- “The Network is Reliable: An informal survey of real-world communications failures” (article)
- Release It!, Second Edition (book)
- Designing Data-Intensive Applications (book)
- Enterprise Integration Patterns (book and website)
- “A Note on Distributed Computing” (classic paper)
- “What we talk about when we talk about distributed systems” (article, talk video, and slides)
- “How do you cut a monolith in half?” (article)
Notes
[1] OK, maybe you’ve thought through all of the issues in your system, and you’re absolutely convinced this is safe. In that case, I’d still recommend reading Designing Data-Intensive Applications, if you haven’t already, just to be sure.



