
In this tutorial I'll explore a QLearning implementation using TensorFlow. I'll discuss the key concepts of QLearning, the role of an Agent, the Model's structure, and updating the model's parameters with tf.GradientTape.
While I won't cover topics like the ADAM Optimizer or the Loss Function here, I encourage you to check out our machine-learning repository for the full Python code, including the snake game implementation (playable game here, qlearning for snake here, and qlearning package here).
My aim is to highlight the essential components of a QLearning example that enables machine learning to master the snake game and offer insightful reading material to help you grasp the inner workings of the code.
Game Capabilities and Limitations
For the code implementation of the game, refer to the machine-learning repository (snake implementation).
The snake game is as you would expect it: a snake that grows each time it “eats” a randomly placed food. The score increases by 1 every time it eats, and the game ends when the snake’s head crashes into its tail or the walls.
Some special considerations were made when creating this game, with the intention of using it for machine learning. First, the snake uses just three actions relative to its direction: “left”, “right,” and “forward.” This removes the need to know where “true north” is. There’s also no concept of “waiting,” nor a “back.” When played by a human, if there are no buttons pressed in X milliseconds, it automatically chooses “forward.”
Finally, there is no difference between a collision with the tail vs one with the walls. For coding simplicity, if one wants to play again after dying, the game class needs to be restarted.
QLearning Overview
QLearning is one of many reinforcement learning algorithms in the field of computer science. Its objective is to maximize the reward that an entity called “agent” grants to the learner. When you give your dog a biscuit for learning to sit, the biscuit is the reward, you are the agent, and your dog is the learner.
The steps of reinforcement learning can be understood as the following, in a general sense:
Environment observation
Deliberating which action to take
Executing such action
Receiving the reward or penalty
Learn from experiences
Iterate
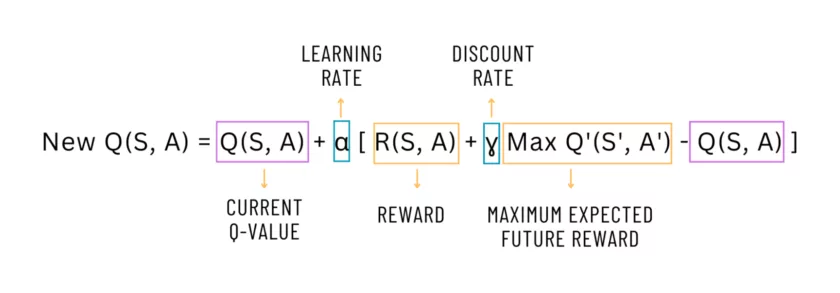
In Q-learning, the “Q” stands for Quality, and it is a learning process that optimizes the strategy of choosing an action given different states. In a bit of technical language: the learner needs to properly map how valuable is an action A, given a state S: Q(A,S). QLearning uses the Bellman Equation to calculate the value of a state, and how good it is to be in that state. Such an equation expresses the relationship between a value function in state 1, and the value function in the following state 2, given a chosen action for state 1.
Here’s another way to think about it: the environment had some state when the learner executed an action, resulting in a change in the environment and maybe a reward obtained. The learner will use the initial state, the action, the reward, and the final state to learn how to properly choose actions that maximize the rewards.
Game Loop
Having gone through QLearning in the broad sense, I can begin focusing on what the Game Loop will look like. The final version of the game loop in the machine learning repository has some additions, which I will cover later in this article.
Before starting the loop, create an instance of the game; and then within the loop, execute the following steps:
Get the state of the game.
Choose an action given the state.
Execute the action and observe its effects: Was food eaten? What is the score? Did the snake die?
For visualization, draw the game on the screen.
Ask the agent to calculate the reward given the effects (the dog can’t calculate its own reward).
The game changes after the action was executed, so get the new state.
Create a record of the following: the initial state, the action chosen, the reward, if the game is over, and the final state.
Train the model once with that single record. (Short-memory).
Store the record for later use.
If the game is over, train over multiple stored records (Experience replay), and reset the game to play again.
The “state” of the game is an abstraction of the relevant things of the game in a given moment. In this case, such important things are: the direction of the snake, the direction of where food is, and if there is immediate danger in the front, in the left, or in the right. Once this code is understood, I hope the reader can successfully explore different state representations (such as, “is danger two movements in front?,” the body length, the distance from the head to each wall, etc).
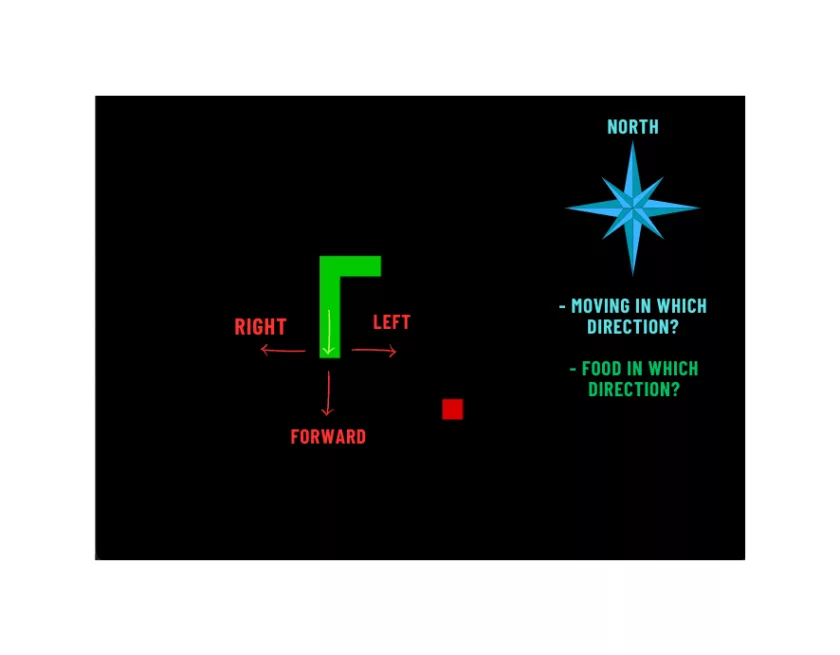
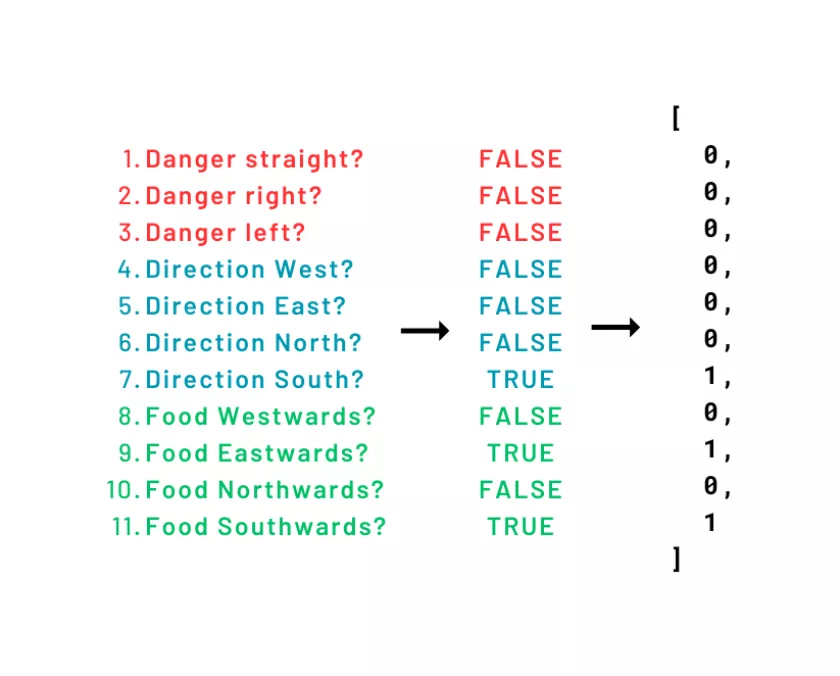
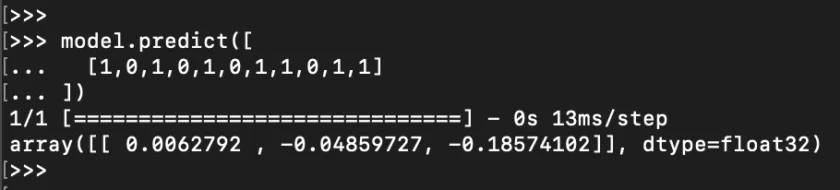
A single prediction from the ML model will output estimated rewards for each of the three available actions. So, “choosing an action” is just executing such a prediction given the state, and choosing the action with the highest expected reward of them all.
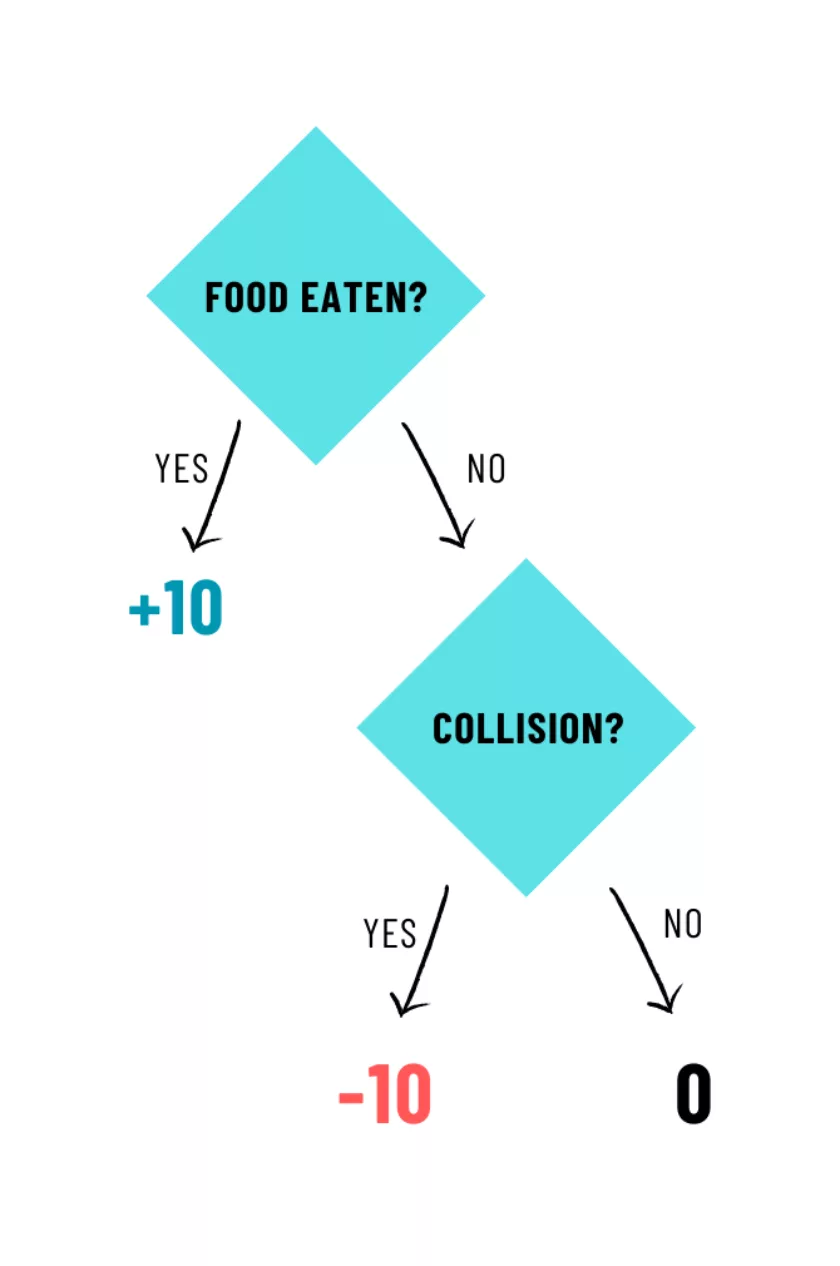
Executing the action and drawing the game is trivial using the SnakeGame code. After executing the action, the game should tell if food was eaten, if the snake died, and the new score. Using the information of whether food was eaten and if the snake died, the agent calculates a reward: the reward for eating is +10 and the penalty for dying is -10, otherwise it is 0.
This model was built to maximize, not minimize, but either option works as long as the reward system is coherent with it.
After the action is executed, the game has changed, so it needs another vector representation of its new state. Appropriately store the first state, the action taken, the reward, the snake’s liveness, and the final state. Train the model once with this single record to ensure every step is considered at least once. If the snake was indeed dead, use the storage to train over multiple different records in no specific order, as introspection or long-term memory. Reset the game if it ended.
Agent
The agent has been mentioned multiple times by now. Personally, getting a grasp of what it should do was more difficult than I expected. Trying to keep responsibilities separated for different classes wasn’t trivial. In the end, I found that the agent is a middleman between the game loop and the model that is actually learning the data.
The model, as smart as it is, should be focused only in learning, so it shouldn’t have capabilities like storing and retrieving objects, or calculating the state of the game. The model just takes previously digested data in the form of vectors, and outputs raw data in the form of vectors. As the model shouldn’t get the game state, it shouldn’t be able to calculate a reward. The agent does everything in between: mapping the game to a vector representation, calculating rewards and penalties, storing dataset records, and instructing the model on when to learn what.
In my implementation it is also doing some other stuff that could be debatable whether it is the agent’s responsibility: translating actions from “model language” (probabilities) to “game language” (concrete final action), and counting the number of games played.
Model
As mentioned previously, the model is only focused on learning. Or, more specifically, in transforming inputs into outputs, and having parameters that can be updated. So, in some sense it doesn’t do very much. It doesn’t even “know” it is playing snake. All it knows is there are some inputs and some outputs. We as humans, and our coding skills in the rest of the program, are the ones translating those outputs as actions for the game, and the game’s state to inputs of the model.
def linear_qnet(input_size: int, hidden_size: int,
output_size: int) -> keras.Model:
"""Creates a 1-hidden-layer dense neural network"""
inputs = keras.layers.Input(shape=input_size, name="Input")
layer1 = keras.layers.Dense(
hidden_size,
activation="relu",
name="Dense_1")(inputs)
action = keras.layers.Dense(output_size, name="Dense_2")(layer1)
return keras.Model(inputs=inputs, outputs=action)
If one full input is a single vector of a game’s state, you could ask: how is it that the model is playing a sequential game? It is certainly not keeping track of previous or future states. At least not explicitly.
Humans can play snake this way too: if you were given a picture of a snake in the middle of a game, could you choose which single action is the best to take? Certainly. Let’s say we gave you random pictures of random games, you could choose a single best action for each one of them.
The model is doing the same thing. However, instead of feeding random pictures when it is playing, we are feeding it sequential pictures that give the illusion of continuity. When the agent tells the model to learn in chunks (retrospection, or long-term memory), those chunks are chosen at random and have no continuity whatsoever; it is just data.
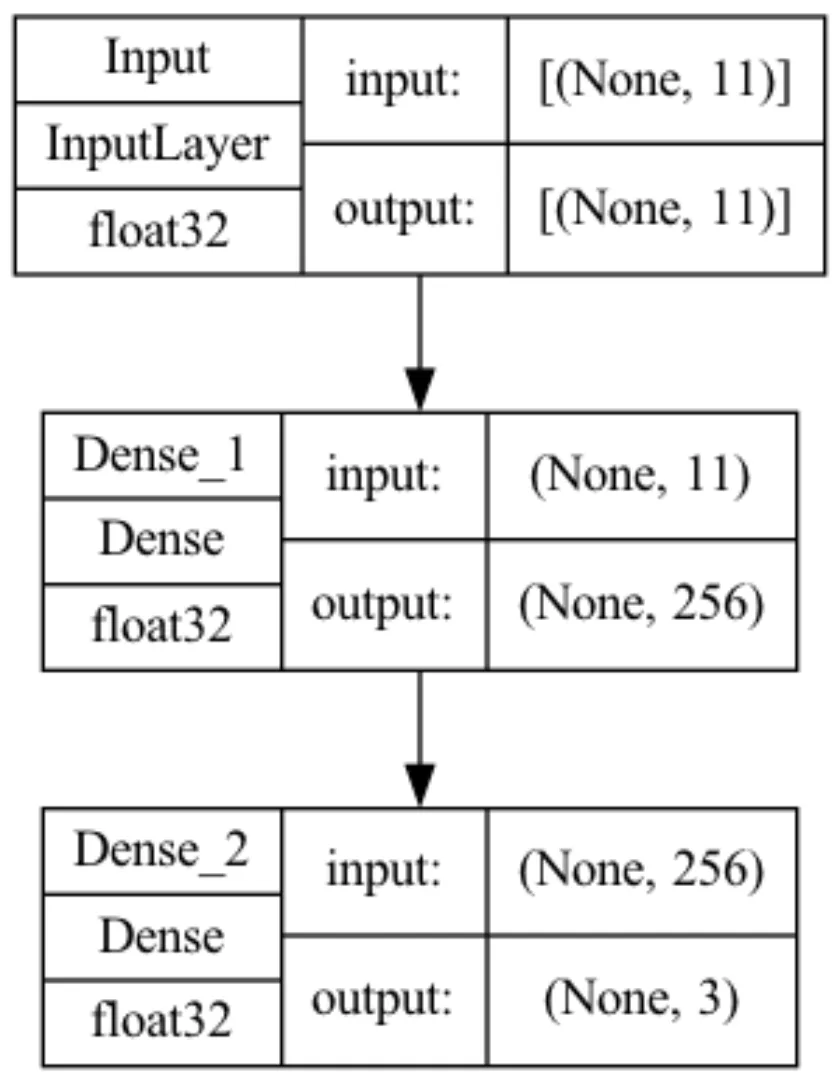
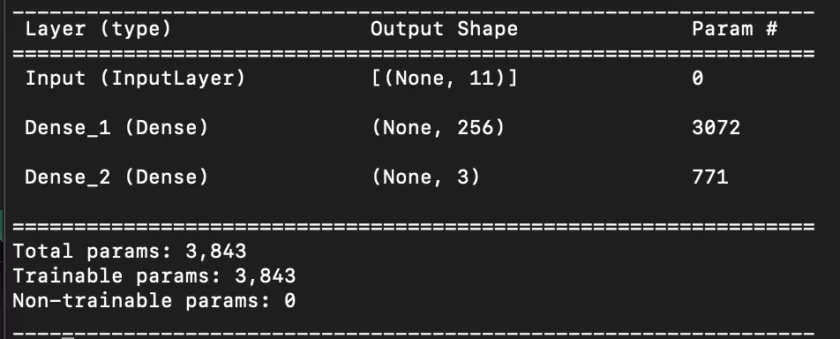
As long as inputs and outputs remain coherent with the rest of the code, the hidden layers of the input (and the model itself) can be experimented with. Our working example is a Sequential Model of 11 inputs and 3 outputs, and a fully connected Dense layer of 256 ReLU units in between, totalling 3843 parameters.
Trainer
The model, simple as it is, can’t update its own parameters. I created another class called QTrainer that is the one calculating the output of the loss function, calculating derivatives for the parameters of the model, and updating those parameters in an efficient way. This class is the one responsible for being initialized with the learning rate; and in QLearning, with the discount factor of the Bellman Equation.
Shooting for the stars, we gave it a go at updating the model’s parameters “ourselves,” or at least to have more control to better understand what is happening under the hood. For that, I used tf.GrafientTape. It was not a trivial task, but I got it working, and I learned a lot from it.
class QTrainer():
"""Trains the given model according to an optimizer and loss function"""
def __init__(self, model, learning_rate=1e-4, gamma=0.9):
"""Uses the ADAM optimizer and MeanSquaredError loss function"""
self.model = model
self.gamma = gamma
self.optimizer = keras.optimizers.Adam(learning_rate=learning_rate)
self.loss_object = keras.losses.MeanSquaredError()
@tf.function
def train_step(self, states, actions, rewards, next_states, dones):
"""
Updates the model's parameters by calculating their derivatives
with respect to the loss function
"""
future_rewards = tf.reduce_max(self.model(next_states), axis=1)
# Q value = reward + discount factor * expected future reward
updated_q_values = rewards + tf.math.multiply(self.gamma, future_rewards)
updated_q_values = tf.math.multiply(updated_q_values, (1 - dones))
masks = actions
with tf.GradientTape() as tape:
# train the model on the states and updated Q-values
q_values = self.model(states) # similar to action_probs
# apply the masks to the Q-values to get the Q-value for the action
# taken
q_action = tf.reduce_sum(tf.multiply(q_values, masks), axis=1)
# calculate loss between new Q-value and old Q-value
loss = self.loss_object(updated_q_values, q_action)
# Backpropagation
grads = tape.gradient(loss, self.model.trainable_variables)
self.optimizer.apply_gradients(
zip(grads, self.model.trainable_variables))
Quoting Tensorflow, the tf.GradientTape is: “an API for automatic differentiation; that is, computing the gradient of a computation with respect to some inputs.” In other words, it is a beautiful way of calculating derivatives for some variables with respect to others. (You can even calculate second derivatives by nesting two gradient tapes, etc). The derivative of the model’s variables is essential to compute the next possible values that will take the model closer to optimal performance.
The `train_step` function is performing two general actions. First, it calculates the new Q-value. The new Q-value is the reward of this state plus the maximum expected reward of the next state having been reduced by a discount factor. However, we only need to keep Q-values for states that did not end in finishing the game.
Finally, the gradients are obtained: the model’s trainable variables with respect to the loss function. The gradients tell the “direction” of where the model “should move” to get better at the task. How “big” a step is taken in such a direction depends on the learning rate. So, the gradients are used by an optimizer to update the model’s parameters efficiently using apply_gradients. The optimizer is internally using the learning rate to “move” just enough for the model to learn and still be stable.
Mental Model of the Data and Its Predictions
The way that the model is being trained creates the following mental understanding of what its outputs mean. The model’s prediction (vector of size 3, for [left, forward, right]), is the answer to the question “What is the expected reward for every possible action given the current state?”
Every prediction for a state will have three values: they correspond to the expected reward for each of the three states. The highest value of them all gives us the value of that state itself. When the predicted values are bigger, the state is more valuable. When the prediction is performed on the current state, this largest value is also telling which action should be taken: the action with the highest expected reward. When the prediction is performed on the next state, we just use it to calculate how valuable the next state becomes.
So, the Q-table is not explicitly kept: there is no table of actions and states that maps into rewards and penalties. The model is the one that can generate each of those values when needed, through its complex internal interactions.
Rewards and penalties are given only when eating and dying, so how does the model learn to “get closer” to the goal? The model’s prediction for a given state is updated with information from the following state. So, with repetition, states that lead directly to the goal will record the reward, and that will be used to record itself in its previous state, and in its previous one and so on. Finally, the reward is “spread” across states, and the further a state is from the goal, the less impact the reward has on it. How big or small is such an impact across preceding states depends on the discount factor parameter.
Optimizations to the Main Idea
QLearning is now working. So far, the model takes too long to train — not because of the model being faulty or the trainer misbehaving, but because of some other factors. In QLearning cases like this, it is common to use what is called Exploration and Exploitation.
In early stages of training, we want the model to choose many random actions, so as to generate many different data records that can be learned from. That is Exploration. As the number of games progress, we allow the model to use what it has learned, little by little; giving it some autonomy. That is Exploitation; exploitation of experience. Eventually, there is no more exploration (randomly choosing actions), and all action selection is trusted to the model.
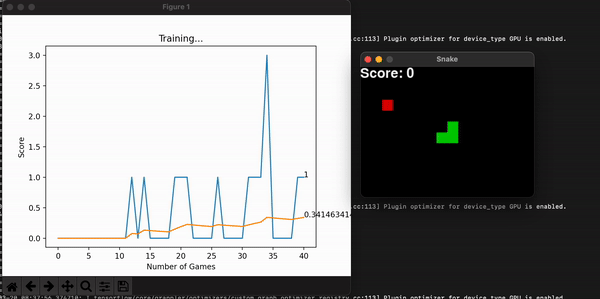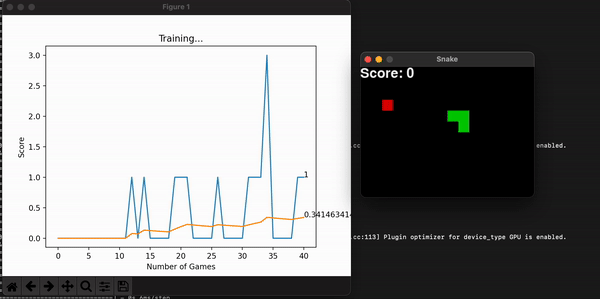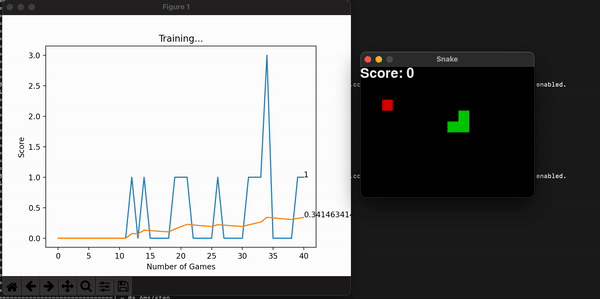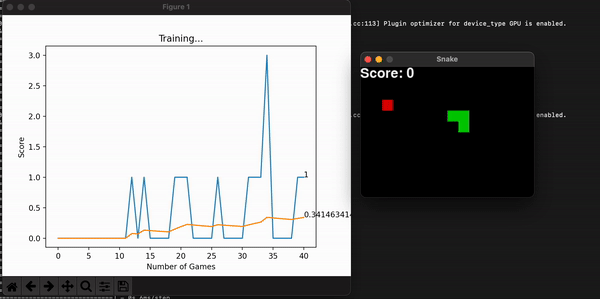
In this game, the snake is penalized every time it collisions. So it is not uncommon for it to learn a simple strategy: avoid crashing. A simple way of doing it is to circle eternally. The model is thinking: well, at least I am not dying… But that doesn’t fulfill our purpose, so we code a stopping condition and give the model a penalty if that happens. There can be multiple ways of coding this, but I chose to count the number of frames and the length of the snake to calculate whether it is doing any advancement at all. Yes, maybe the snake could have eaten the food if left alone a little longer, but knowing whether a program will stop is a difficult problem, and time waits for no one.
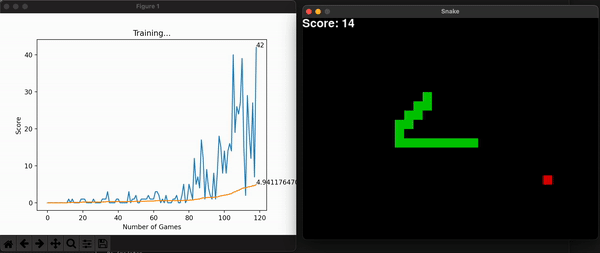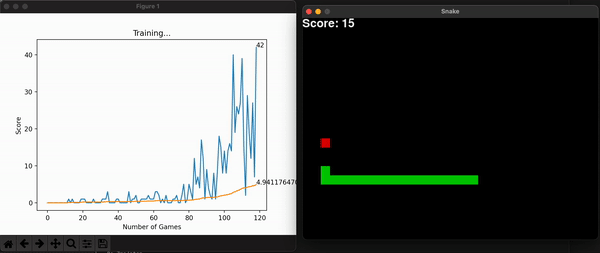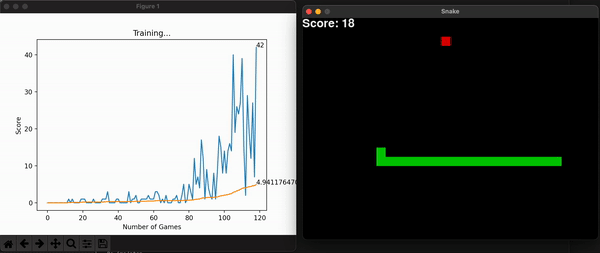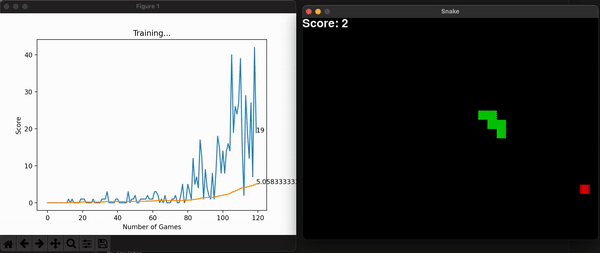
Another improvement made was to grow the size of the board incrementally alongside the model’s highest scores. This way, at the beginning it is more likely for the snake to stumble upon food and get excited with its reward. As it gets better, you can increase the maximum score by increasing the board size, and so overall learning speed increases (in seconds). This improvement makes sense because we are watching the model learn live, and we want it to make sense to us humans.
Another alternative is to “artificially” build some data records that represent states significant to us: what the reward would be if the snake is next to the food and eats it, or next to a wall and crashes, or next to a wall and avoids it, etc.
Finally but not less important, the dataset will grow incredibly rapidly, as it’s generating one record per game state. To keep the dataset from growing infinitely and yet remain significant, we use a “deque,” which is a data structure that drops old records when it is at maximum capacity. We know every record was used at least once in short-term memory, and for them to be dropped means they had the chance to be randomly selected for training again and for multiple times in long-term memory.
Administrative Tasks
Once QLearning is implemented and the model is learning fast enough so that the developer is not idle staring at the computer, it is very useful to understand how “good” the entire configuration is, and to be able to store the model’s parameters for later use.
It is common to store checkpoints of the training process. Not only are they available if they happen to be the “best” possible so far, but if the process crashes for some reason, we won’t need to start from scratch again. Always save your work.
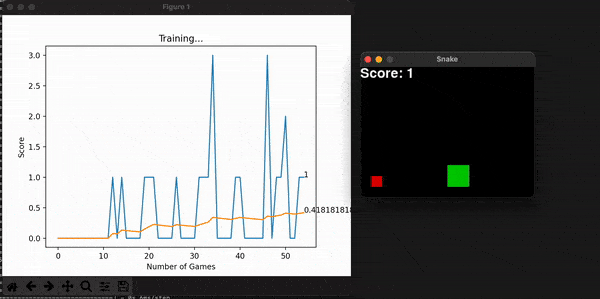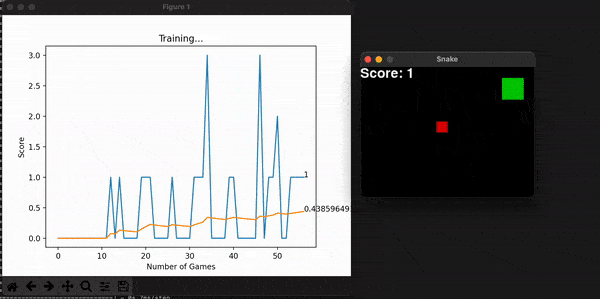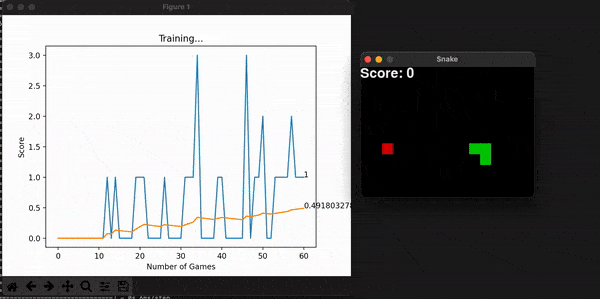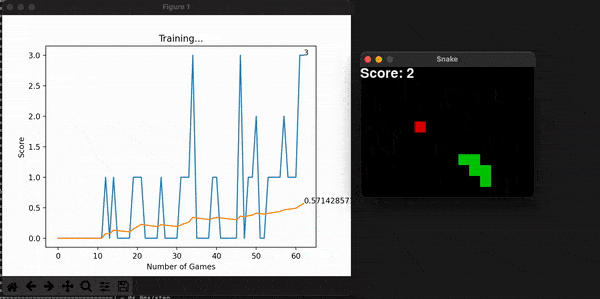
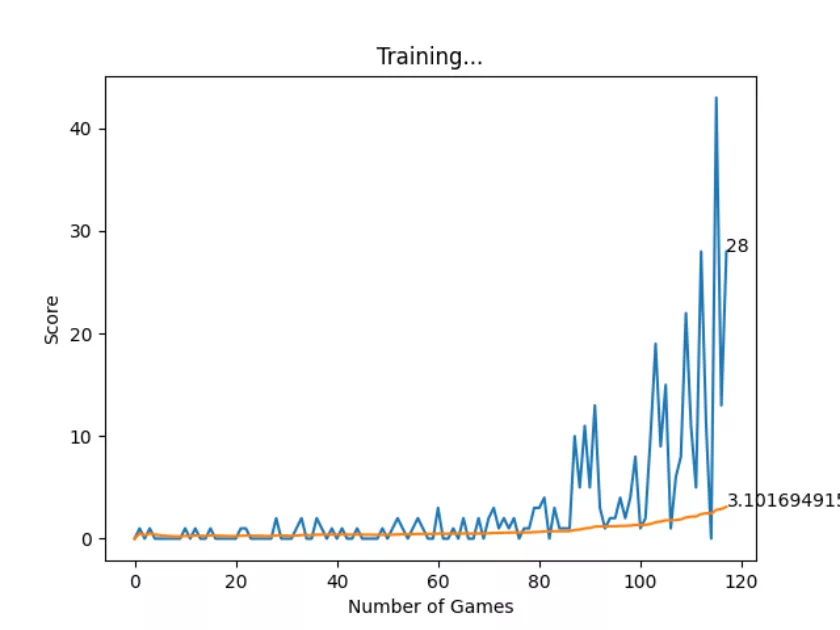
Some other useful information is the model’s score for every game. With them, I can calculate the overall mean score, which is expected to increase, thus showing the model is consistently getting better at the game. You can store this history data, or plot it alongside the snake game that is unfolding live and get a useful toolset to assess the entire program. Embedding the program into a command line interface is the final touch in making it useful for a long time, for many people.
Next Steps
Some questions arise that open the door for further improvements. First, the state that we are using is a combination of the snake’s perspective and the map’s true north: if the food was also measured with regards to the snake’s left, right, and forward directions, maybe there wouldn’t be a need to check the snake’s direction, and the game state could be much smaller.
And finally, the Q-value filters for states that do not lead to a game over. But that state is the same one that is creating the -10 penalty. Does that mean the penalty is having no effect on the training? This question is worth some digging.
In this article I have gone through everything needed to properly understand Q-learning, and I hope the readers can create their own process for an entirely different use case. If that is the case, feel free to submit your creation as a Pull Request to the machine learning repository, it would delight us to review and include it!
If you are not there yet, feel free to clone the repo and explore with the game yourself, try breaking the Q-learning process in creative ways and learn while doing so. Once fully understood you might encounter bugs and misdemeanors that I could have missed, if you do, please let me know!



