

I'm sure at some point you've had to draw some boxes and arrows to describe the high level view of how a system works. But what are those boxes and arrows called? We often use terms like microservices, monolith, REST, or event driven, but what are these?
As part of my apprenticeship I've been reading about formal Software Architecture concepts and definitions, and throughout this post I'll explain some of those concepts as they apply to a project I've also been working on during my apprenticeship: a JSON-RPC Playground Console.
Software Architecture is...
I'll use the definition that Roy Fielding, one of the main authors of the HTTP spec and the creator of the REST style, gave in his doctorate dissertation paper (If you're interested in Software Architecture, I can't recommend this paper enough).
A software architecture is an abstraction of the run-time elements of a software system during some phase of its operation. A system may be composed of many levels of abstraction and many phases of operation, each with its own software architecture.
Architecture is abstraction
Implementation details can be abstracted away when describing an architecture. Does it matter if an authentication service is written in Elixir or Java? Or is the role that it plays within the system - authenticating users - what we should focus on?
Architecture is about run-time
Source code structure is not a system's architecture. Different applications can share the same libraries or modules and yet be completely disconnected from each other when the system is live. We focus on what is processing data and how it is moved around.
Architecture is focused in a specific phase of operation
Not every component will play a role at all times or be part of every process flow. The components involved and their configuration when a system shuts down can be very different than those involved in a system's normal mode of operation.
Architecture is nested
When abstracting an element's implementation, we're ignoring details that are not relevant for the current architectural point of view. If we change our focus to a deeper level, a new architecture will emerge with its own set of elements and configuration. We'll find many nested architectures until elements are simple enough that they cannot be decomposed anymore.
A software architecture is created as the result of a series of decisions, each bringing a set of properties and constraints. Whether they are explicit in a diagram or simply living in the minds of architects and developers, there is an understanding or intention of what those decisions and constraints should be. As a system evolves, those initial decisions can very well not match the reality of an architecture. If these differences are undesired or accidental, we say the architecture has eroded, creating an architecture drift or "technical debt."
Case study: JSON-RPC Console
One of our clients’ platform is composed of dozens of JVM microservices that talk to each other using the JSON-RPC 2.0 protocol. Each service declares its RPC API using a set of Java interfaces that get published as a "Service-API" library (JAR) in a common repository. Clients that want to interact with a service simply have to declare its API JAR as a project dependency. A platform library will generate objects that implement such interfaces and make them available to the rest of the code through dependency injection. From the code perspective you're just calling a regular method, but in the background the platform library is executing an RPC call and handling all the plumbing for you. And this is a great productivity booster when writing code!
However, to manually test any of these RPC methods (using a tool like Postman or curl, for example), one has to find the right code base, manually inspect the service interface, its methods and parameters (with possibly many levels of nested objects), and manually build the required JSON payload to execute the call. Documentation helps, but it's hard to keep it up to date.
I decided to create a GUI application that autogenerates forms that can easily be filled in to call any RPC method exposed by a service. The forms are generated from a Service Description file, compatible with JSON-RPC 2.0, that gets created by analyzing the Service-API JAR libraries. By using the same source as the actual code that runs in production, they're guaranteed to stay up to date.
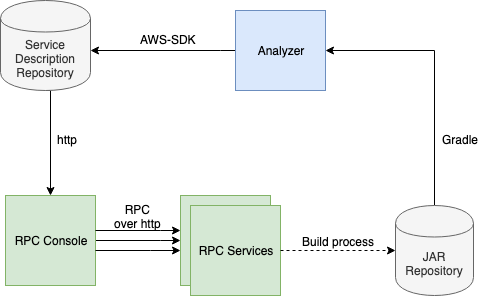
Architecture Elements
Architecting a system means making a series of decisions that shape the configuration for the different elements that form a system: components, connectors and data.
Components
A component is an abstract unit of software instructions and internal state that provides a transformation or performs computations of data via its interface. Components are defined by the service they provide to other components, rather by the implementation behind their interface. If certain behavior cannot be discerned by the rest of the components, then such behavior is not part of the architecture.
In the example:
-
RPC Console:Transforms a service description to a set of forms, captures user input, executes RPC calls, and displays their result. -
RPC Server:Receives RPC requests, computes them, and returns the result. -
Analyzer:Transforms Service-API JARs to a Service Description. -
JAR Repository:Stores and serves Service-API JARs. -
Service Description Repository:Stores and serves Service Descriptions.
Note how when we define the RPC Server component, for the purpose of this architecture's point of view, we're not interested in what specific functionality the RPC Server provides, since it's not relevant to the rest of the components. We are even grouping many different instances of this component as equals, even though in reality they will functionally behave very differently—one could be a Users service, while the other could be a Books service.
Connectors
Connectors enable communication and data transfer between different components. They don't transform the data, they just move it between the different components through their interfaces. Internally however, when looking at the architecture of one specific connector, we may find that it's actually composed by a subsystem of components that take the data, transform it into a better format for the transmission, send it to the other end, and reverse the transformation before passing it to the rest of the system. Since those transformations are not visible to the rest of the system, we can abstract them away at a higher level.
In the example:
-
RPC Client:Starts transmission of the RPC call. -
RPC Server:Receives RPC request and returns RPC response. -
HTTP client:Starts HTTP connection to fetch Service Description. -
AWS Library:Transfers a Service Description from the Analyzer to the Service Description Repository. -
Gradle Library:Transfers Service-API JARs dependencies from the JAR Repository to the Analyzer.
In the case of both the AWS Library and the Gradle Library, we're not directly responsible for how these data transfers happen. We can then use a high-level view of the connectors and ignore the details of their implementation.
Data
Many software architecture definitions don't mention data as a core concept, which I believe gives an incomplete picture. Data is the reason a system exists, and is sometimes even the main factor driving a system's configuration. Data is defined as the information that is transferred from one component to another via a connector.
In the example:
-
Service Description:Describes the available RPC methods exposed by the services, in a JSON-RPC 2.0 compatible structure. It includes information like server URLs, method names, parameters, and types. -
RPC Request:Includes the RPC method name and its parameters. -
RPC Result:The result of the execution of an RPC invocation. -
Service-API JAR:JAR file containing the Java interfaces for the RPC Services.
Architectural Styles
An architectural style is a named collection of architectural design decisions, that when applied under a specific context, puts constraints on the different system elements, their configuration and the way they can relate to each other, and in turn generate a solution with well known beneficial properties for the system.
Styles are a mechanism for categorizing architectures and for defining their common characteristics. Each style provides an abstraction for the interactions of components, capturing the essence of a pattern of interaction by ignoring the incidental details of the rest of the architecture. A style can focus on only certain aspects of an architecture, and they can even be combined to generate more complex or hybrid styles.
Client-Server, Microservices, Monolithic, and even REST are all different architectural styles that you have most likely seen applied to dozens of heterogeneous systems.
Creating our own style
If you're familiar with tools like Swagger for REST APIs, you probably noticed that my JSON-RPC project has some similarities to it. While my console uses a Service Description tailored for JSON-RPC based services as input, REST APIs have the OpenAPI Standard. These specifications formats that are generated from the source code of a service are a powerful pattern that enable the creation of many different consumer tools: documentation navigators, clients code generators, mock servers, etc...
Let's try to define a generic architectural style for this family of tools that can be applied to any other protocol to get the same benefits: I'll call it the Service Description style.
Service Description style
Let's start by defining the different elements of the architecture
Data elements:
- Target source code: Source code for a Target service's interface.
- Service Description: Protocol-specific format that, following the protocol standard, can describe the interface of any Target service.
Components:
- Generator: Automates the creation of a Service Description from the Target source code and publishes it to the Provider.
- Repository: Stores and serves a Service Description.
- Client: Consumes a Service Description from the Repository and uses it as the only source to provide functionality that's dynamically tailored for the Target service.
Connectors:
- Generator -> Repository: Transmits a Service Description from the Generator to the Repository.
- Repository -> Client: Transmits a Service Description from the Repository to the Client.
A Service Description has to be created from the source code. Clients need an always-up-to-date Service Description to be functional since they know nothing about the specifics of the Target service unless included in the Service Description. The primary source of truth is the code, and if the process is not automated there's a high risk of the Service Description falling out of date and having a broken client. That doesn't mean that a Service Description can't be built by hand. There are a lot of valid use cases for doing that—for example, if you want to have a mock server before the actual implementation. However, a system that relies on manual tasks will not be considered to be an implementation of this architecture style.
Note that we put no constraints on how the source code is made available to the Generator. In fact, the Generator can even be implemented as a step in the Target's build process (for example with a Maven plugin). A Service description should follow a protocol standard. One of the main benefits of this architecture is reusability of clients against many different Target services that use the same protocol, and for that reason a Service Description can't have knowledge of particular implementation details that would only work for one specific service. What functionality a Client provides is not part of the architecture: a Client can interact with the Target service (for example for a playground Console) or not at all (in the case of static documentation). The main restriction behind Clients is that they should have zero knowledge of the implementation details of a Target service other than the information that the Service Description contains. Connectors are defined very loosely since we're not putting any restrictions on how information is transferred.
I hope after reading this post you will now have vocabulary to describe the parts of software architecture that we work with every day. As an exercise, try to imagine how an implementation of the Service Description style would look like for a Websockets-based service, and if you write a tool for it, let me know!



